
AI 算力主權的物理邊界,HBM 資本門檻與去中心化網路的長尾反擊
從半導體物理極限到 DePIN 網路,AI 算力權力結構正在發生什麼改變


Hi,歡迎來到拉菲的Substack
讓我們都能用輕鬆的方式,成為更好的自己。Let’s Chill and Better!!
開始專欄寫作後,才發現自己會在「學術研究的完整性」與「自媒體敘事張力」之間舉棋不定。想要在簡化複雜資訊的同時,又希望建立一個可信任的視角。這種既要又要的狀態真的是思緒糾結大挑戰。
這次文章將從半導體物理的底層限制出發,層層遞進地剖析資本如何透過硬體實現壟斷,以及去中心化架構,如何成為一種必然浮現的產業路徑。
前言
人類文明的競爭籌碼正在經歷場結構性位移。過去,評估產業霸權的核心指標是金融體系的穩定性與貨幣儲備。然而進入 AI 時代,算力因為具備了貨幣的所有特性,包含稀缺性、流動性以及生產力支撐,成為數位世界中最基礎的價值尺度。
當競爭邏輯被推進到由半導體物理邊界所決定的層次,資源定義權的爭奪也隨之升級。晶片主權的核心咽喉,落在高頻寬記憶體(High Bandwidth Memory,HBM)之上。它成為進入頂級算力領域的重要門檻,使得 HBM 的供應能力,直接限制了 AI 系統的擴展速度1。
HBM 構築的物理高牆
在半導體產業的第一線,我們正目睹經典計算架構遭遇史上最強烈的物理挑戰。傳統電腦遵循馮·紐曼架構(Von Neumann Architecture),其核心邏輯是將運算單元與儲存單元分開,兩者透過電路排線進行數據交換。
這種架構進入高階運算(High Performance Computing,HPC)時代後,面臨數據傳輸速度遠低於運算速度的問題,並在業界被定義為記憶體牆(Memory Wall)。
用生活化的方式舉例,想像一位動作極快的頂級廚師(GPU處理器),卻必須頻繁跑向大門外的倉庫(DRAM記憶體)拿取食材,使得料理速度(算力)受到限制。即使廚師刀工再快,大部分時間都在等待食材送達。
而 HBM 直接打破了這種空間限制,透過矽穿孔(Through Silicon Via,TSV)的晶片垂直電連接與先進封裝技術,將記憶體晶片堆疊並直接緊貼在運算核心旁。這等於將倉庫直接搬進了廚房,擺廚師的伸手可及之處,造就了 HBM 與先進製程成為高階算力的標配。
然而,製造現實層面,HBM生產週期比傳統 DRAM 長二個月以上,且受限於複雜的技術門檻,目前整體良率(Yield Rate)僅維持在 50% 至 60% 之間,遠低於標準記憶體 90% 以上的成熟水準。且每生產相同容量的 HBM,就需要比 DDR5 多出 3 倍晶圓需求,等於在技術成本環節,直接將供應鏈階級化。
資本市場的智慧壟斷
以往半導體製程發展會遵循摩爾定律,由技術突破驅動成本下降,但現在情勢則是資本規模直接定義了天花板。每一顆頂級 AI 晶片背後,都代表著數萬美金的固定成本。這在產業內部形成了一道天然門檻,只有具備極高資本支出承擔能力的產業巨頭,才擁有進入高階模型訓練場的門票。2
這種算力與資本的強耦合,導致了中心化智慧的風險。當全球最強大的預測引擎與邏輯定義權被鎖定在少數資本實體手中,對於全球研究單位或中小型開發者而言,智慧主權正面臨挑戰。這種封閉性不僅體現在專利與硬體上,更體現在對數據解釋權的壟斷,壓抑人類文明技術路徑的多樣性,讓創新的方向被侷限在符合資本回報率的範疇內。
後 HBM 時代的技術分流
物理極限與高昂成本,促使產業開始探索不同於 HBM 的替代路徑。這些嘗試並非意圖取代 HBM,而是在極致性能之外,尋求更具經濟效率的架構選項。
例如,記憶體內運算(Computing in Memory,CIM)嘗試在儲存單元內完成部分指令,以降低資料搬運次數。Cerebras 則選擇透過大容量 SRAM 的晶圓級架構,擴張片上儲存空間,繞過外部頻寬瓶頸。
在軟體層面,模型量化與壓縮技術同樣扮演關鍵角色,讓 AI 模型在不高度依賴 HBM 頻寬的前提下,仍能完成具實用價值的推理任務。
這些發展共同指向一個明確趨勢:後 HBM 時代的算力結構,將走向分流,而非單一路徑的全面壟斷。
從 OpenClaw 映照終端執行的結構轉移
近期引發熱議的 OpenClaw,正好印證了這種架構分流的迫切需求。當 AI 從單純的對話模型轉向具備行動能力的執行代理(AI Agent),人工智慧的產出場景開始從雲端中心向終端產品快速滲透。
這類應用要求極低的反應延遲與高度的隱私安全,在實務面上,難以每次都仰賴雲端昂貴的 HBM 訓練集群進行判斷。
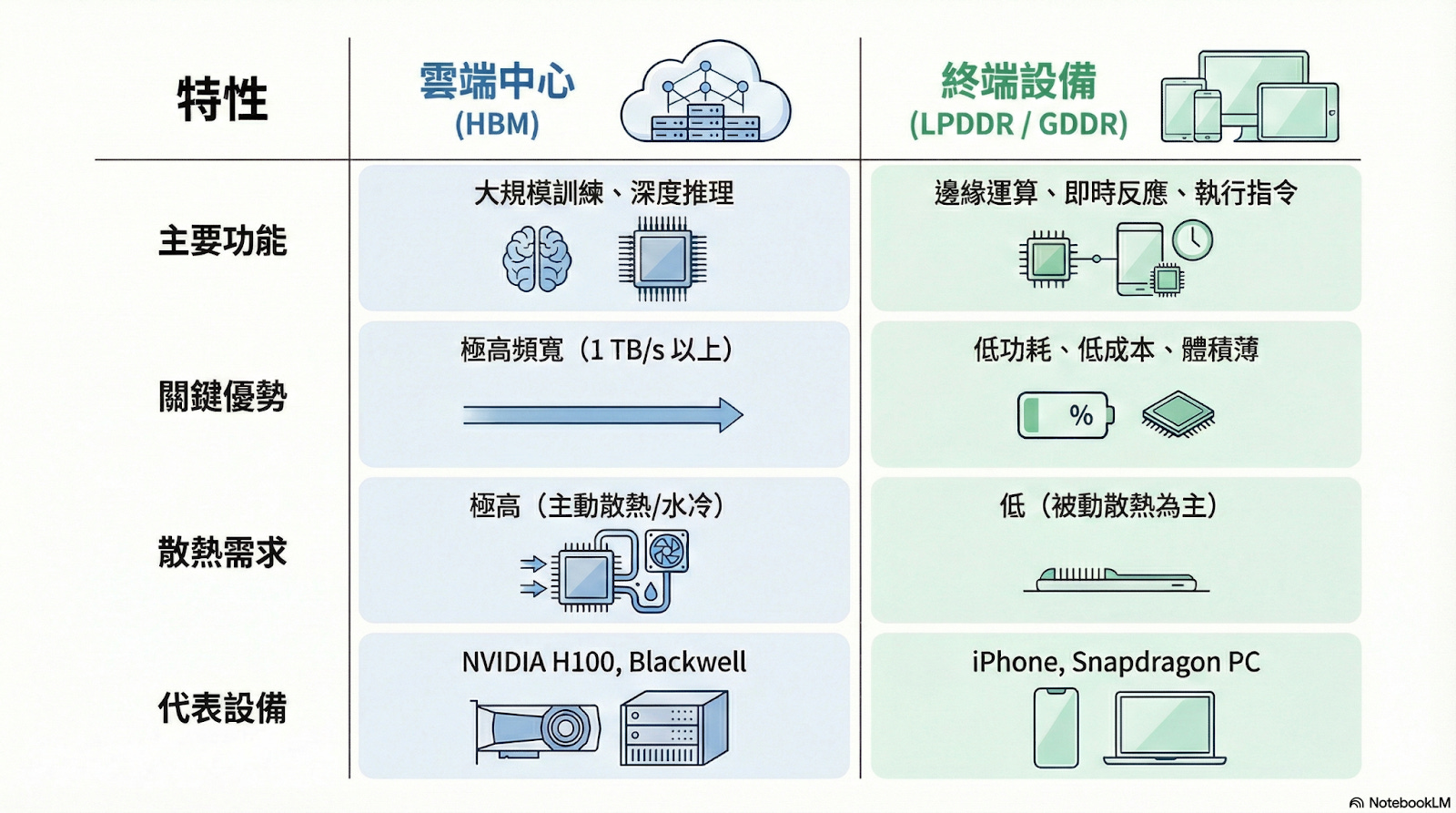
終端設備在硬體條件上,與雲端機房存在根本差異。智慧型手機、個人電腦與自動化裝置,多半採用以節能為核心的 LPDDR(低功耗雙倍數據速率記憶體),並普遍採用 PoP(Package-on-Package)封裝技術,將記憶體直接堆疊在處理器上方,實現極度有限的空間內功耗效率的最優化。
這樣的硬體落差,最終定義了兩套不同的演算法邏輯。雲端 HBM 支撐的是數據吞吐的持續擴展,而終端 LPDDR 則是挑戰在有限的記憶體容量內,透過模型量化與結構簡化,完成精準而即時的推理任務。
去中心化實體基礎設施網路
這種向邊緣執行力的位移,正是去中心化敘事從理想主義轉向商業價值的關鍵時刻。正如加密貨幣曾挑戰法幣的中心化體制,現在的 DePIN(Decentralized Physical Infrastructure Networks,去中心化實體基礎設施網路) 則試圖在硬體特權之外,建立一套更具韌性的資源網絡。
當 AI 開始在各類微小終端上長出手腳,技術演進開始算力分配轉型。HBM的雲端核心負責耗能深度訓練,分佈在最末端的終端設備,讓原本被忽視的、基於 LPDDR 架構的碎片化資源,則負責廣泛的環境執行。這種分散化需求,具備了重新被組織的商業價值。DePIN 的出現,讓硬體設備持有者能直接參與全球算力供應,這在邏輯上打破了資本巨頭對底層基礎設施的絕對壟斷。
啟動算力的長尾效應
去中心化所開啟的競爭重心,並未聚焦於極端的大模型訓練效率,而隨著架構演進,逐步轉向算力長尾效應的啟動、釋放與再組織。
透過整合分散於終端的 GPU、個人電腦與邊緣運算節點,去中心化協議得以構建出高度彈性、具備成本優勢的 AI 推理市場(Inference Market),並將既有存量資源重新編織為可運作的產業網路。
在此模式,區塊鏈扮演著無需人工介入的程式化結算與分佈式驗證層。透過智慧合約實現了A2A的「按需求計價、即時結算到帳」自動化機制,讓原本碎片化的硬體資源,在無需人工協調的情況下完成可信協作,並解決跨國結算瓶頸。
對開發者而言,這不僅是一道抗審查防線,更是一個能實際改善成本結構的流動性池。閒置或低使用率的硬體,得以在輕量化推理與特定場景任務中重新釋放價值,形塑以存量為核心的二級算力市場。
若從時間成本來看,這種轉變的價值更為明顯。傳統晶片從投片到出貨約需三個月,涉及 HBM 與先進封裝時,週期往往拉長至半年以上。這種由製造流程決定的時間慣性,使算力供給難以即時回應需求波動。DePIN 透過即時調度既有資源,填補供應鏈延遲所產生的算力空窗,使資源配置得以跳脫物理生產節奏的限制。
結論
關注物理邊界中的結構性機會
對於正在尋找 AI 下一波機會的人士而言,理解半導體的物理邊界,是為了看清權力的來源;而布局去中心化架構,則是為了提前對齊市場正在形成的方向。
從當前的技術與產業條件來看,未來的算力格局,正逐步走向主權核心與液態邊緣並存的結構。
在這樣的分工之下,HBM 訓練集群將繼續承擔人類智慧的深度累積角色,作為高度資本密集的重工業體系存在,負責支撐最宏大的科學問題與基礎模型訓練。
同時,隨著 OpenClaw 等應用產品被實際部署與採用,去中心化推理網路正逐步向邊緣展開,將這些智慧能量帶入具體場景之中,完成即時且可驗證的執行任務。
這場圍繞資源分配權展開的結構轉換,已開始重塑 AI 的技術與商業版圖。我們既需要清楚認知 HBM 所代表的性能上限,也必須主動辨識那些正在成形的分散化路徑。除了關注頂級晶片的產能配置,在物理高牆之外,如何參與算力釋放與架構翻轉的過程,正成為關鍵的策略選擇。
最終,AI 不會只是被集中於昂貴機房中的權力象徵,而是透過分散式架構,逐步回到人類社會的各個微觀單元。對能夠看懂並提早佈局這條演進路徑的人而言,去中心化不只是趨勢,而是一種可被主動掌握的結構位置。